
Meta currently operates 14 data centers around the world. This rapidly expanding global data center footprint poses new challenges for service owners and for our infrastructure management systems. Systems like Twine, which we use to scale cluster management, and RAS, which handles perpetual region-wide resource allocation, have provided the abstractions and automation necessary for service owners to be machine-agnostic within a region. However, as we expand our number of data center regions, we need new approaches to global service and capacity management.
That’s why we’ve created new systems, called Global Reservations Service and Regional Fluidity, that determine the best placement for a service based on intent, needs, and current congestion.
Twine and RAS allowed service owners to be machine-agnostic within a region and to view the data center as a computer. But we want to take this concept to the next level — beyond the data center. Our goal is for service owners to be region-agnostic, which means they can manage any service at any data center. Once they’ve become region-agnostic, service owners can operate with a computer’s level of abstraction — making it possible to view the entire world as a computer.
As we prepare for a growing number of regions with different failure characteristics, we have to transform our approach to capacity management. The solution starts with continuously evolving our disaster-readiness strategy and changing how we plan for disaster-readiness buffer capacity.
Having more regions also means redistributing capacity more often to increase volume in new regions, as well as more frequent hardware decommissions and refreshes. Many of today’s systems provide only regional abstractions, which limits an infrastructure’s ability to automate movements across regions. Additionally, many of today’s service owners hard-code specific regions and manually compute the capacity required to be disaster-ready.
We often don’t know service owners’ intentions for using specific regions. As a result, our infrastructure provides less flexibility for shifting capacity across regions to optimize for different goals or to be more efficient. At Meta, we realized we needed to start thinking more holistically about the solution and develop a longer-term vision of transparent, automated global-capacity management.
When scaling our global capacity, Meta initially scoped approaches to two common service types:
When considering placement of a latency-sensitive service, we must also take into account the placement of the service’s upstream and downstream dependencies. Collectively, our infrastructure needs to place these services near one another to minimize latency. However, for latency-tolerant services, we do not have this constraint.
By using infrastructure that has the flexibility to change the placement of a service, we can improve the performance of the products. Our Global Reservations Service simplifies capacity management for latency-tolerant services, while the Regional Fluidity system simplifies capacity management for latency-sensitive services.
Global Reservations help simplify reasoning about fault tolerance for service owners. When service owners request the capacity needed to serve their workloads, Global Reservations automatically adds and resizes disaster-readiness buffers over time to provide fault tolerance. This process works well for latency-tolerant services that are easily movable in isolation.
We built Global Reservations on top of the regional capacity management foundation provided by RAS, which we presented last year at Systems @Scale. When service owners create regional reservations to acquire capacity for their workloads, the reservations provide strong guarantees about the placement of capacity. To determine the best placement for latency needs, RAS then performs continuous region-wide optimizations to improve the placement. 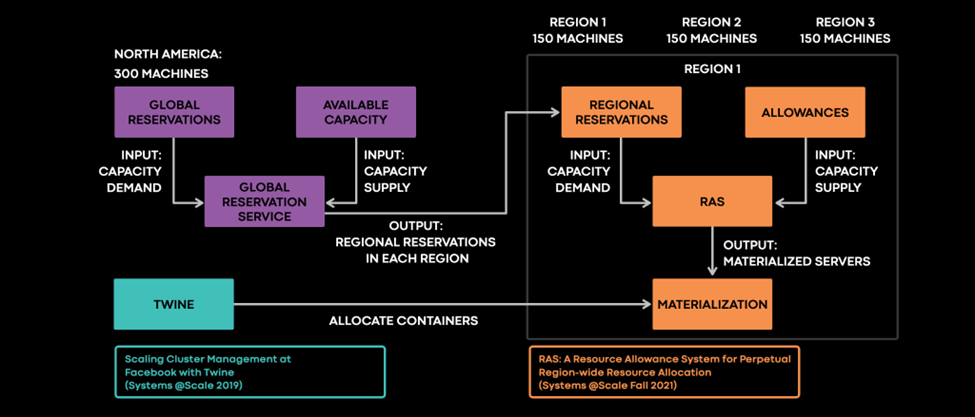
Previously, strong capacity management guarantees existed only at the regional level. Service owners had to monitor how much capacity to provision in each region for fault tolerance. As a result, the fault tolerance and capacity reasoning for each region became increasingly complex. As our scale continued to increase, we realized that this level of guarantee no longer provided the performance that our products required and that people who used them expected.
When we performed periodic hardware decommissions and refreshes, we observed that a subset of these services often did not have latency constraints. We then created Global Reservations to give service owners a simpler way to reason about their capacity — globally and with guarantees.
Instead of creating individual reservations within each region, the service owner now creates a single global reservation. Then, the Global Reservation Service determines how much capacity is needed in each region. Because these services are latency-tolerant, we can easily shift them across regions to the placement that provides the performance necessary for continuous global optimization. After developing the Global Reservations Service, we modified Twine to run at a global scope to allocate containers on global reservations.
To illustrate how the service owner interacts with Global Reservations, the figure below shows a hypothetical service owner’s request for 300 servers in the North America continental locality. In this example, the service owner is amenable to any region in North America that provides sufficient servers to meet their demand and tolerate the loss of any region.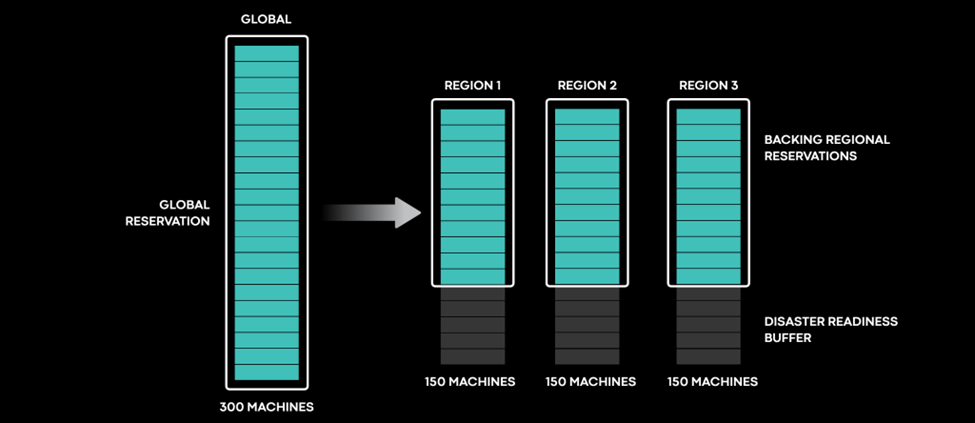
To meet that need, the Global Reservations Service provisions 150 servers each in three different regions, for a total of 450 servers. If we lose any region, the extra 150 machines serve as the disaster-readiness buffer to provide sufficient capacity.
As we increase the number of regions, the Global Reservations Service automatically spreads capacity over more of them. For example, we can allocate 30 servers in each of 11 regions. Spreading servers across more regions creates a more efficient disaster-readiness buffer.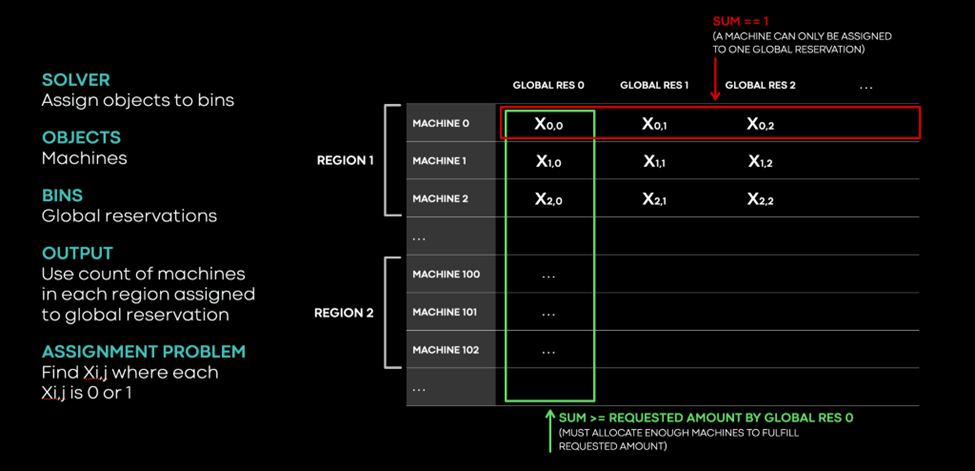
At the core of the Global Reservations Service, the Solver assigns objects to bins; the objects are machines and the bins are global reservations. This format enables the encoding of various constraints and objectives.
In Table X, rows correspond to machines and columns to global reservations. Each entry contains an assignment variable X (either 0 or 1), which indicates whether that machine is assigned to that global reservation. Because we can assign a machine to exactly one global reservation, the variables in the red row must add up to 1. Additionally, we designate one special placeholder reservation as “unassigned” to hold all unassigned servers.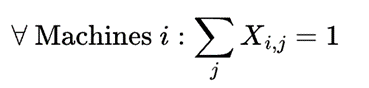
Because we must assign enough machines to fulfill the request, the variables in the green column must equal the sum of at least the amount requested by Global Reservation 0.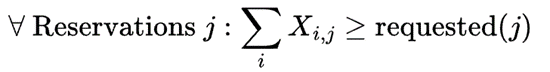
Since we must provide fault tolerance if any one region becomes unavailable, the total number of machines assigned to a global reservation minus the amount in the largest region for that reservation must be at least the amount requested by the global reservation.
For example, to minimize the total number of allocated servers in our fleet, we use the following code: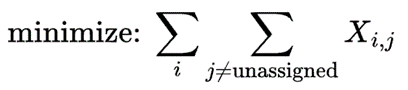
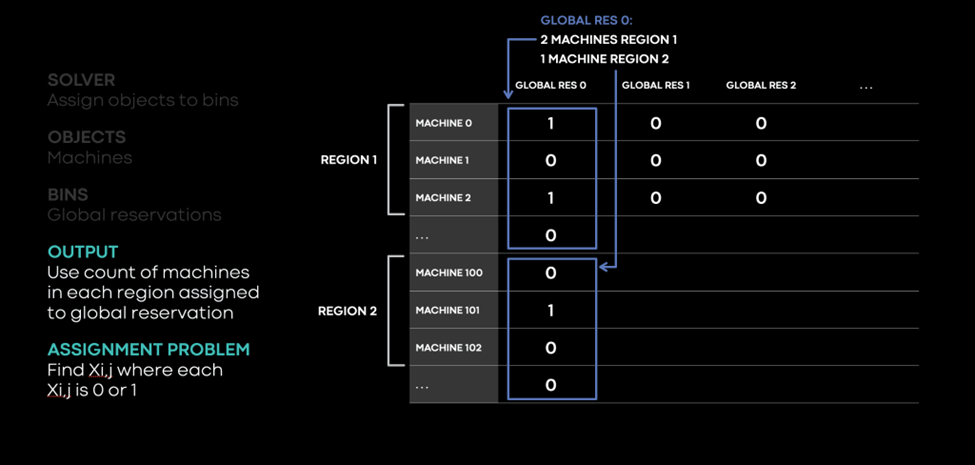
The solver also translates other types of constraints and objectives into a mixed-integer linear programming problem. If the assignments of these variables satisfies all the constraints, the Solver optimizes for the various objectives. For example, if Global Reservation 0 has two machines assigned in Region 1 and one machine assigned in Region 2, the solver generates the regional reservations for RAS in each region and continuously works to adjust the placement.
Overall, global reservations help simplify global service management. The Global Reservations Service performs continuous optimization and improves service placement over time, making it possible to optimize infrastructure for other objectives. For example, if we remove capacity in a region to facilitate a hardware refresh, global reservations help us automatically redistribute capacity to other regions.
Because global reservations are declarative and intent-based, service owners encode their intent in global reservations instead of hard-coding specific regions. The infrastructure now has the flexibility to improve the placement over time while still satisfying the service owner’s intent.
However, this approach does not work for latency-sensitive services, for which we must consider placement of upstream and downstream dependencies as well.
To scale global capacity management for latency-sensitive services, we must be able to place and move them safely. This requires us to understand latency and geographic distribution requirements by attributing demand for the services. After modeling services and understanding demand, we can use regional fluidity to rebalance the services by redistributing the demand source. This system leverages the capabilities of infrastructure to safely move services toward a globally optimized state.
Most latency-sensitive services have placement requirements to reduce and/or eliminate cross-region network requests (see the figure below).
This diagram illustrates how service capacity requirements relate to two demand sources: users of the Facebook app and users of the Instagram app. To minimize user latency for these demand sources, the news feed services must be located in the same regions as the application front-end services that handle requests from the demand sources. This means service capacity cannot be allocated arbitrarily. The capacity must be allocated in proportion to the set of front-end drivers of the demand sources.
Attribution of demand sources involves the following:
Once we understand the demand sources for our services, we can shift the demand across regions to redistribute our capacity globally. In the figure below, we shift demand for a single demand source (the Facebook demand source) from Region A to Region B. In the initial state, we observe how much of each service’s demand is attributed to the various demand sources. In this example, Facebook drives 80 percent of the first service’s traffic in Region A and 75 percent in Region B, with enough capacity in both regions to handle the load.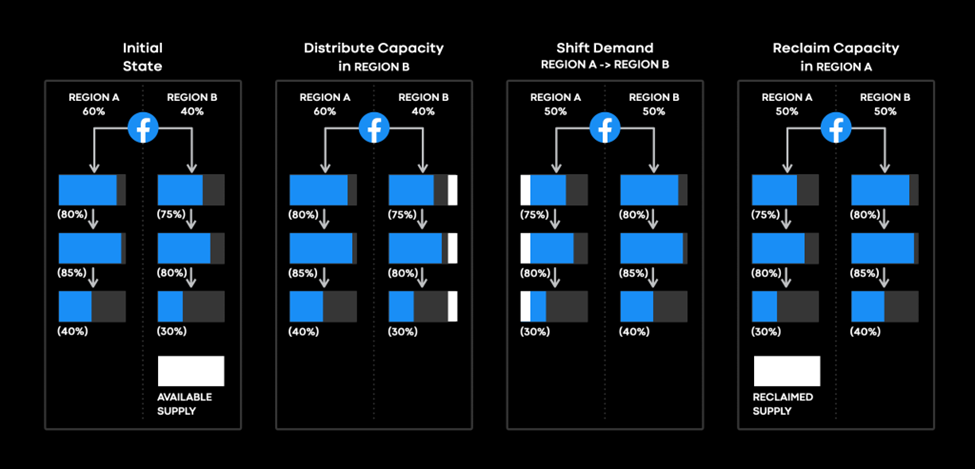
If we want to reclaim capacity in Region A and have a surplus of supply in Region B, we start by distributing additional capacity in Region B. Next, we shift some of the Facebook demand source traffic from Region A to Region B. The capacity must be distributed before the traffic shift to prevent overloading the service in that region. Once the traffic demand in Region A has decreased, we can reclaim the excess capacity.
As the above example illustrated, this process is complex even for a simple two-region setup. When there are many regions, we need an automated solution for planning capacity. Similar to Global Reservations, the process of deriving a placement plan can be modeled as an assignment problem in which we assign capacity to services in specific regions.
The Solver produces a placement plan for various demand sources by using the service dependencies and traffic ratios as constraints to determine how much capacity can be shifted safely. Then the Solver considers the constraints, optimization functions, demand attribution, and supply, and generates a feasible plan. Finally, the Solver performs global optimizations, allowing more efficient operation at a global scope.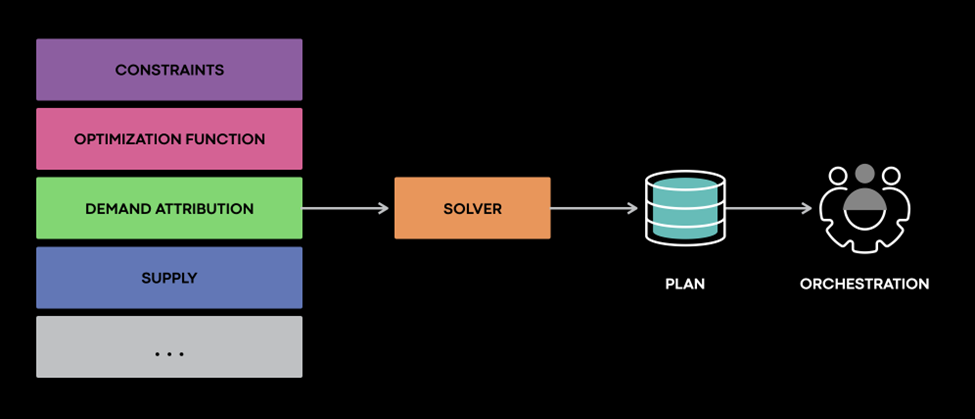
Regional Fluidity introduces the following new elements to provide first-class fluidity:
After the Solver generates a plan, the Orchestrator executes that plan.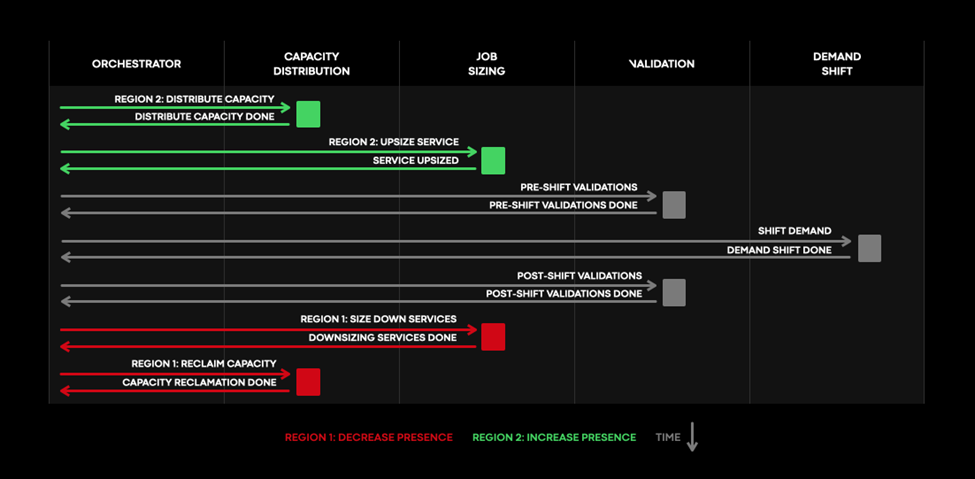
The Orchestrator drives the execution of the plan from end to end, sequencing various actions to ensure the safety of all services at all times. Automation drives the actions as much as possible, but some require human intervention.
For example, to shift a demand source from Region A to Region B, we must:
These steps ensure that both regions maintain a safe state during the shift. To temporarily upsize the double-occupancy buffer, we request the needed capacity at a temporarily increased cost, which allows for safe and automatic regional capacity shifts.
Overall, Regional Fluidity provides the following benefits by managing global capacity for infrastructure:
Meta’s solutions currently address two points in the service spectrum: latency-tolerant services and latency-sensitive services. However, additional types of services with different requirements lie along that spectrum. For example, AI training workloads are more fluid than storage services, but they require data to be local to the training data. Additionally, stateful or storage systems, such as databases and caches, are typically multitenant services. However, copying data often increases the time required to shift these services. To manage network traffic more effectively, we need to provide global capacity management for more types of services.
At Meta, we want to develop fully automated, transparent, global capacity management for all services and to empower service owners to reason about capacity globally. By providing the abstractions necessary to model and understand service intent, we can provide the infrastructure with enough flexibility to improve placement over time. We’ve made significant progress for many types of services, but more work lies ahead.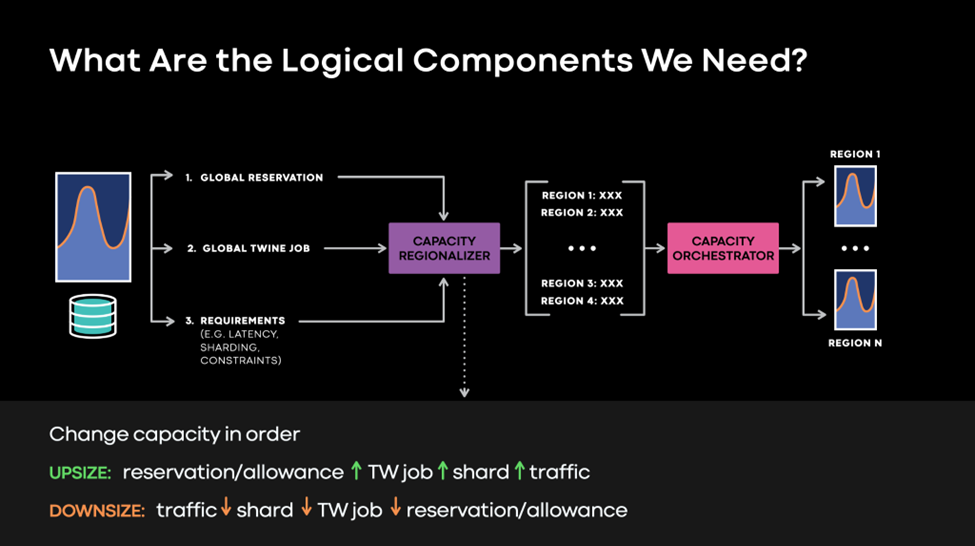
The first step is to update the expectations service owners have for infrastructure. Instead of reasoning about regional Twine jobs and reservations, service owners can now operate on the global level. The infrastructure then automatically decides the regional placement of their workloads. Global reservations also capture more intent from service owners, such as latency constraints and sharding constraints.
A capacity regionalizer component, which runs continuously to improve placement, determines the exact regional capacity breakdown and then safely orchestrates the necessary changes across the various global abstractions. The capacity orchestrator also supports services that require more planning or orchestration.
For example, we can integrate a global shard placement system into global capacity management much like we orchestrate regional shifts. However, we can now add extra steps in a specific sequence to support globally sharded systems. The capacity orchestrator instructs the global shard management system to build additional shard replicas in the new region after the Twine job has been upsized and before the traffic shift. Similarly, the capacity orchestrator instructs the global shard management system to drop the shard replicas in the old region before downsizing the Twine job. This allows for safer, fully automated regional shifts for globally sharded services.
Much of this work is in progress or still being designed, and we have many exciting challenges ahead:
We’ve taken the important first step toward seeing the world as a computer with global capacity management. But our journey is only 1 percent finished. At Meta, we are excited for the future, and we look forward to seeing our vision become reality.
Meta believes in building community through open source technology. Explore our latest projects in Artificial Intelligence, Data Infrastructure, Development Tools, Front End, Languages, Platforms, Security, Virtual Reality, and more.
Engineering at Meta is a technical news resource for engineers interested in how we solve large-scale technical challenges at Meta.
To help personalize content, tailor and measure ads, and provide a safer experience, we use cookies. By clicking or navigating the site, you agree to allow our collection of information on and off Facebook through cookies. Learn more, including about available controls: Cookies Policy


